对话状态追踪 (Dialogue State Tracking, DST) 是任务型对话系统 (Task-Oriented Dialogue System, TOD) 的核心模块.
DST 的目标是 提取用户目标 (User Goal) 和 意图, 并将其编码为 对话状态 (Dialogue State). 所谓 Dialogue State, 是一组 意图-槽位-槽位值 组合.
在单领域对话系统 (Single-Domain TOD) 中, Dialogue State 可以表示为
<Intent, Slot, Value>组成的集合;
在多领域对话系统 (Multi-Domain TOD) 中, 需要将 Domain 加入对话状态中, 即对话状态为<Domain, Intent, Slot, Value>四元组组成的集合.
为了表述上的方便, 可以认为对话状态由<Domain-Intent, Slot, Value>三元组组成.
下面是一个对话状态的示例:
[
("restaurant-inform", "price", "cheap"),
("restaurant-inform", "people", "8"),
("attraction-inform", "type", "architecture"),
...
]一些传统的 DST 方法, 将 DST 建模为 (多标签)分类问题 (Multi-Label Classification Problem). 分类问题需要提前枚举所有的类别标签, 因此需要提前建立较为完备的槽位值本体库 (Ontology).
ontology, “本体; 本体论”
- [UN, philosophy] Ontology is the branch of philosophy that deals with the nature of existence. “本体论”
- [UN, logic] the set of entities presupposed by a theory
ontology 由 onto- + -logy 构成,
其中词根 onto- 来源于希腊词汇 on (所有格 ontos), 含义是 “a being, individual; being, existence”.
后缀 -logy 是 “学说” 的意思.
使用分类问题建模 DST 的主要问题如下:
- 常常无法得到完备的本体库
- 本体库过于庞大
同时在对话系统中, 特别是多领域对话系统中, 槽位的具体值可能并非来自本轮对话, 甚至来自于其它 Domain 的某个其它类型的槽位. 这就涉及到 多轮映射 (Multi-Turn Mapping) 及 领域迁移 (Domain Transfering) 问题.
比如, Hotel 领域中的酒店位置信息 (假设 Hotel 域有 addr 类型槽位) 很可能在后续的 Taxi 领域对话中成为 Departure 的槽位值.
总结上述 DST 相关问题如下:
- 如何在本体库不完备情况下实现 DST?
- 如何解决 DST 中的 多轮映射 和 领域迁移问题?
由 香港科技大学 提出的 TRADE (TRAnsferable Dialogue StatE Generator) 方法较好地解决了上述问题.
TRADE: Transferable Dialogue State Generator
TRADE 由 香港科技大学 的 Chien-Sheng Wu et al. 于 2019 年提出, 论文 Transferable multi-domain state generator for task-oriented dialogue systems.
为了解决 本体库不完备 下的 DST 问题, TRADE 将 DST 使用了 State Generator 的方法, 将 DST 建模为序列生成问题 (而非传统的分类问题), 无须构建本体库, 即可完成 槽位值生成.
为了解决 多轮映射问题, TRADE 使用了最近的 L 轮对话作为输入.
为了解决 领域迁移 问题, TRADE 使用 Copy Mechanism 技术, 该技术对 Zero-shot DST 和 Few-shot DST 也有较为明显的效果.
从模型构成上, TRADE 主要由三个部分组成:
- Utterance Encoder
- Slot Gate
- Slot Generator
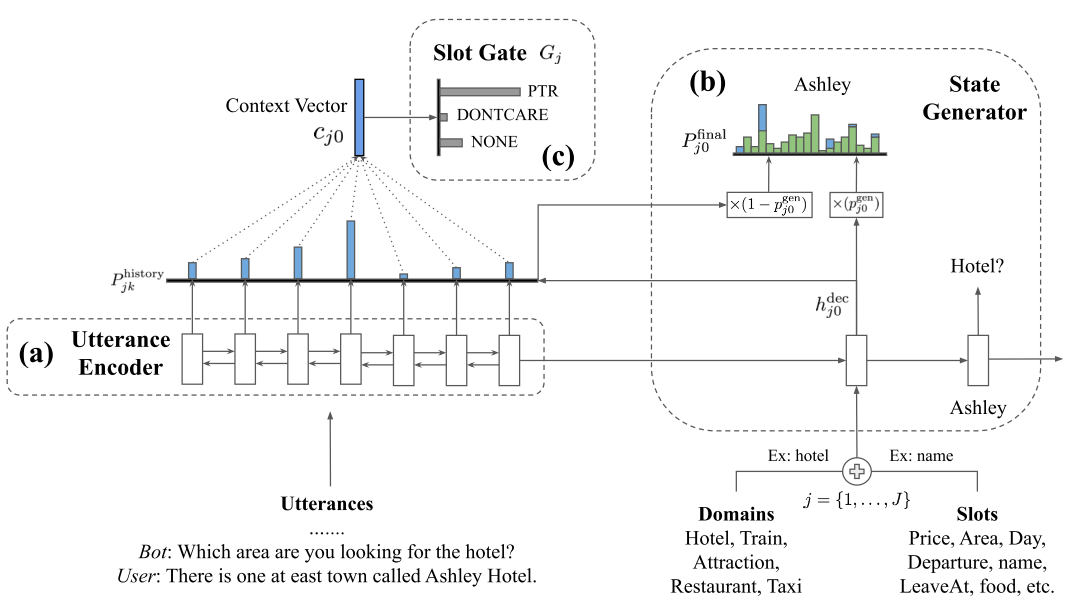
整体上, 使用了经典的 Encoder-Decoder 架构来实现序列生成模型. 其中 Utterance Encoder 用来编码对话文本信息; Slot Generator 作为 Decoder, 负责槽位值生成. Slot Gate 是一个三分类器, 用于判断是否需要使用生成的值填充该槽位.
Utterance Encoder
TRADE 的 Utterance Encoder 没有特殊的设计, 使用常规的 LSTM 或GRU 即可.
为了解决 多轮映射 问题, TRADE 将最近的 l 轮对话内容拼接在一起编码, 数学表示如下:
其中 分别表示拼接后的文本长度, Embedding Size 和 Hidden Size.
Slot Generator
Slot Generator 是 TRADE 的解码器, 也使用了 RNN 来生成对应的槽位值序列.
TRADE 对每一个槽位 Domain-Slot 都需要执行一遍解码过程. 我们以 来代表一个 Domain-Slot 槽位, 来看一看 TRADE 的槽位值生成过程.
对于解码器, 我们已知的输入信息有:
- 编码器输出序列编码 及 隐状态 . (这里省去了表示轮次的下标 )
- 当前正在处理的槽位
- 槽位词表 及 对应的 嵌入矩阵
- 所有 Token 对应的总词表 及 嵌入矩阵
- 仅限训练时: 槽位值目标序列
提示
- 槽位词表在构建时, 可以将 d 和 s 分别作为 Token 加入词表中 相对于将
d-s整体作为 Token 可以减小词表体积, 同时方便 d 和 s 的多样组合;- 在具体嵌入时, 可以将 d 和 s 的嵌入向量叠加
对于槽位 , 其槽位值生成过程如下
-
获得 的嵌入向量
-
GRU 初始状态设置为编码器的输出状态
-
解码 Token
-
使用 Token 对应的嵌入向量 作为 GRU 的输入. 特别地, 当 时,
-
使用 GRU 解码, 得到隐状态
其中 ,
- 解码器隐状态 与 编码器序列编码 计算 Attention
其中 是 上下文编码, 是每个序列编码向量 对应的权重
-
将 映射到 上下文向量 空间.
(这里可以使用 FC + Softmax, 也可以使用其它方式. 比如 ConvLab2 就使用了torch.scatter_add()方式, 将 Utterance 中每个单词对应的 Attention 权重 叠加, 作为对应词汇的概率, 这样只有输入序列中出现的词才会的概率大于 0) -
解码器隐状态 与 嵌入矩阵 计算 Attention, 得到 Pointer 向量
- 计算权重因子
- 加权 和 , 得到 的概率分布
- 解码
-
-
槽位 的槽位值
Slot Gate
Slot Gate 是一个三分类器, 目标类别有:
ptrnonedontcare
Slot Gate 只需要在解码槽位 的槽位值的第一个 Token 时判断即可.
Slot Gate 使用最基础的 FC + Softmax 网络即可. 输入 的上下文编码向量 , Slot Gate 的工作流程为:
Zero-shot / Few-shot DST
先回忆一下 TRADE 解码器的输入数据:
- 编码器输出序列编码 及 隐状态
- 当前正在处理的槽位
- 槽位词表 及 对应的 嵌入矩阵
- 所有 Token 对应的总词表 及 嵌入矩阵
- 仅限训练时: 槽位值目标序列:
在 Zero-shot 场景下, 目标 Domain 和/或 Slot 在训练数据未曾出现过, 因此无法获得 对应的嵌入向量. 这种情况下的 DST 是非常困难的.
在 Few-shot 场景下, 可以认为槽位词表 是完备的, 只不过对于新的 Domain 和 Slot, 其嵌入向量是欠学习的.
Few-shot 场景常用的学习方法是 持续学习 (Continual Learning).
论文采用了两种持续学习方法来 Fine-tune 模型:
- EWC (Elastic Weight Consolidation): Overcoming catastrophic forgetting in neural networks, Kirkpatrick et al, 2017
- GEM (Gradient Episodic Memory): Episodic memory for continual model learning, Nagy et al, 2017
关于持续学习, 我们将在后续的博客中再进行介绍.
ConvLab2 实现
在 ConvLab2 中, TRADE 的模型代码在 convlab2/dst/trade/multiwoz/models/TRADE.py 中实现.
TRADE 论文中的相关技术简介
Copy Mechanism
Copy Mechanism 分为三大类:
- Index-based Copy
- Pointer networks, Vinyals et al, 2015
- Hard-gated Copy
- Pointing the Unknown Words, Gulcehre et al, 2016
- Mem2Seq: Effectively Incorporating Knowledge Bases into End-to-End Task-Oriented Dialog Systems, Madotto et al, 2018
- Global-to-local memory pointer networks for task-oriented dialogue, Wu et al, 2019
- Soft-gated Copy
Continual Learning
- EWC: Overcoming catastrophic forgetting in neural networks, Kirkpatrick et al, 2017
- GEM: Episodic memory for continual model learning, Nagy et al, 2017